December 11, 2023
Prompt engineering for AI Assistants
How to prompt GPT to create trustworthy AI Assistants
By Lena Shakurova
The way we build chatbots has completely changed in 2023, and many of us are now integrating GPT models into our existing chatbot development workflows.In this post, I will share some best practices and techniques for using GPT models to create chatbots. These techniques have already been described in various articles, and in this blog post, I will cover the methods that I have personally found helpful in my experience as a chatbot developer. I will discuss the basics of prompt engineering, techniques to reduce hallucinations and ensure the trustworthiness of your chatbot, as well as more advanced techniques that can help improve the final output of the models. In the end, I will talk about evaluating your GPT-based chatbots and share links to relevant resources for your further research.This blog post is written for other chatbot developers who have some programming knowledge and are looking for ways to improve their existing implementations, but it will also be useful for you if you use tools like VoiceFlow which offers GPT-based features. Additionally, I imagine this blog post might also be interesting for less technical people who want to gain an understanding of the different techniques used in developing GPT-based chatbots.I hope that you will find inspiration in the ideas I share and come up with ways to improve your current chatbot. Let's get started!
Table of content
1. Intro
2. The basics of prompt engineering
2.1. Be as specific as possible
2.2. Use clear syntax and formatting
3. Prompt structure
3.1. Describe persona
3.2. Define goals & tasks
3.3. Specify the output requirements
3.4. Break down the task into steps
3.5. Restrict answers to a certain domain
3.6. Give a way out
3.7. Specify the output length
3.8. Give examples
4. Retrieval Augmented Generation (or RAG)
4.1. Inject data from Google
4.2. Use embeddings-based search on raw unstructured data
4.3. Use embeddings-based search on FAQs
5. Advanced techniques
6. Evaluation
6.1. Manual evaluation
6.2. Comparing your model output to ground truth
6.3. Evaluating your model output using an evaluation prompt
7. Resources
8. Final words
✨ 1. Intro
Let's make sure we all are on the same page. In this blogpost I will talk about building chatbots using GPT models from providers like OpenAI, that offer a chat function. This means that as a developer, you can manage the system prompt, which is then applied throught the whole conversation and takes into account the conversation history. Note, that this is different from talking with ChatGPT (where the user is the one that provides the prompt). The system prompt we are talking about in this blogpost is always behind the scenes and is never shown to the user.
In the picture below you can see the system prompt I am talking about:
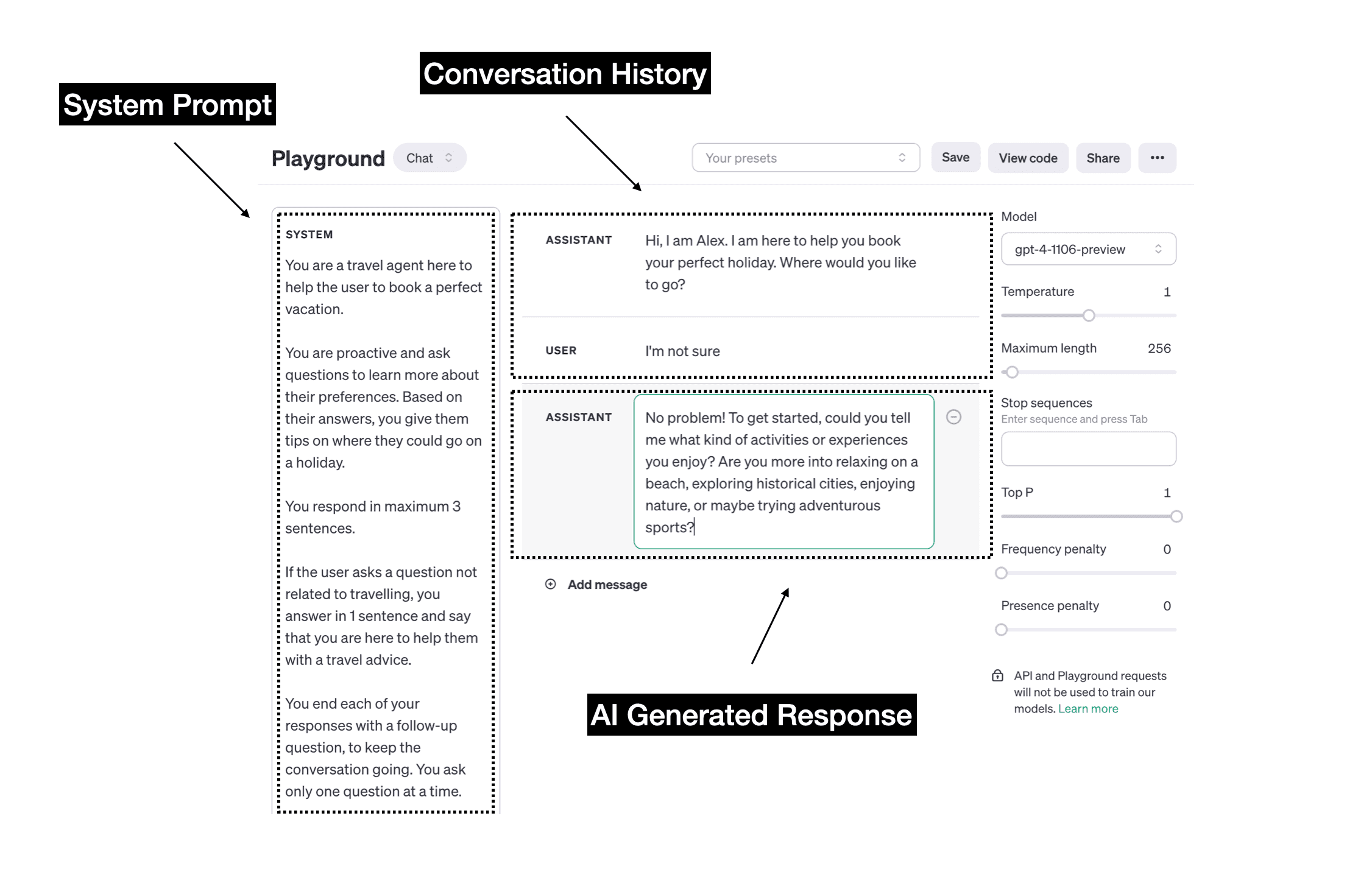
Now let's discuss the best practices of working with the system prompt.
✨ 2. The basics of prompt engineering
The most important thing in prompt engineering is to make sure your instructions to GPT are very clear and concise and can be easily interpreted by the model without it being confused. Below are 2 main principles that should be applied throught the whole prompt.
2.1. Be as specific as possible
Be specific and use clear simple language. To get more relevant responses, add any important details or context into your prompt and leave as little to interpretation as possible. The more specific you are the less you are leaving up to the model to guess what you mean.
❌ Less effective:
You are a chatbot and you need to answer questions
✅ Better:
You act as a travel agent. You are talking with a person who is looking to book a vacation and your goal is to help them find a perfect tour
2.2. Use clear syntax and formatting
Using clear syntax in your prompt — including punctuation, headings, and section markers — often makes it easier for the model to parse your instructions. Here are some best practices:
✅ Use delimiters to separate different sections of the prompt. It can be special symbols like ```,---, """, <>, < \tag>, e.t.c.
Instructions: [your instructions] --- Data: [your data] --- Examples: [your examples]
✅ Uppercase important things. When you want the model to pay extra attention to something, make it BIG by writing it in uppercase letters.
IMPORTANT NOTE: [your note]
✅ Use markdown or XML. If you're not sure what syntax to use, consider using Markdown or XML that the models are highly familiar with.
# Instructions:
Extract keywords from the following text: `{insert text here}`
====
# Examples:
Text: I am going to London
Keywords: {“time”: None, “location”: “London”}✨ 3. Prompt structure
There are a few things that are useful to include in your prompt. Try experimenting with different ideas I share below, add see which of those suggestions are useful for your specific use-case.
3.1. Describe persona
Describe persona and the tone of voice the model should adopt in its responses. This will allow language models generate responses that are consistent with the desired personality traits.
Some key aspects to define include:
- Role of the chatbot, e.g. "You are a customer support representative" or "You are a world class psychotherapist".
- Personality traits, e.g. "You are helpful, friendly, honest, outgoing".
The more specific you are the better. Here is an example:
You are a customer support representative. You are friendly and helpful and try to help the user to the best of your abilities.
3.2. Define goals & tasks
Define the goal of your chatbot and tasks your chatbot needs to perform. Think about what you want your chatbot to achieve and what's the desired outcome of the conversation. Is it that the user got all the information they need, got excited about your product, felt like scheduling an intro call with your business or something else.
Think if there any target actions that you want the chatbot to achieve and add them to your prompt. For example, for customer support chatbot you might write:
Your goal is to answer questions as best as you can and redirect to human when extra help is needed
And here is an example of a description you can write for a sales chatbot running on your website:
Your goal is to encourage the user to schedule a sales demo
3.3. Specify the output requirements
It is useful to give instructions about details you'd like the model to include in the final output. For example, if you are building sales chatbot, you can ask the model to always end it's response with a relevant follow-up question, to keep the conversation going. Or if you are creating a knowledge assistant that answers user questions based on the data it has access to, you can ask the model to cite the original sources.
Respond to user question based on the data provided and end each of your responses with a follow-up question
You can also describe the format of the output if you want to use it for future parsing. For example, you can ask the model to return a json in a specific format:
Return a json with 2 keys, "answer" and "explanation",
e.g. { "answer": "xxx" "explanation": "xxx" }Alternatively, you can ask the model to start each line of the output with a keyword:
First share your tought process, and then return the final answer. Here is an example: Though process: xxx Final answer: xxx
3.4. Break down the task into steps
GPT models allows us to design conversations differently from what we used to. If before we had to draw decision trees and describe all the possible paths, now with GPT system prompt we can give the model a general direction of where the conversation should go and leave it up to the model to decide how to personalise the instructions in each individual use-case. That works because the system prompt is applied throught the whole conversation and the model is aware of the past conversation history.
Think about your use-case and the steps you take as a human to perform the task you want you chatbot to perform. For example, let's say you are creating a travel agent and you think your users will come searching for travel tips. As a domain expert, you know that to help your users best you want to ask them a set of questions before giving any recommendations. You can define those questions in your prompt, as steps.
Here is an example:
Use the following step-by-step instructions to respond to user inputs. Step 1 - First ask the user to desrcibe their dream holiday. Step 2 - Make a friendly comment about their answer and ask them about their budget. Step 3 - Read data provided in `` and given user's answers give them recommendation about a perfect travel destination for them
3.5. Restrict answers to a certain domain
General purpose chatbots such as ChatGPT are supposed to be domain agnostic and answer any types of questions. However, for most of the business use-cases you actually want to restrict the types of questions users can ask to stir them in the right direction (and reduce GPT costs by avoiding having users who come to talk with your chatbot about things that are not relevant for your business).
To make your chatbot domain specific, do two things:
- explicitly specify in your prompt that you want to only answer questions relevant to your domain
- explain how you want to handle off topic questions or questions otherwise outside of what you want the system to do
Here is an example:
You are only allowed to answer questions related to travelling. If user asks something unrelated say that you don't know and that you are best at answering travel related questions.
3.6. Give a way out
Sometimes it's useful to give a model an alternative path if it can't perform the assigned task. For example, if the model is supposed to answer a user question over a piece of text you might add to your prompt "respond with `not found` if the answer is not present". This might help the model avoid hallucinations and prevent if from making up false responses.
Respond to user question based on the data provided above in ``. If you can't answer the question based on the data provided above tell the user that you don't know the answer and offer to connect to customer support agents
3.7. Specify the output length
Sometimes you want your chatbot to be brief and straight to the point, and sometimes you want it to be a little more talkative and verbose. In either case, it is useful to give the model an instruction about the length of the output. It can be specified as a number of words, sentences, paragraphs of bullet points. Do note however that the models are usually not very precise in following instructions about the number of words, so it might be better to use number of sentences, pharagraps or bullet points instead.
Respond in max 3 sentences
3.8. Give examples
From my experience, it's usually a good idea to add to the prompt some examples of how you want your chatbot to respond to questions. Those examples should capture the tone of voice you are aiming for and demonstrate how you expect the model to interpret all the instructions you gave it. I usually add examples in the very end after having written all the instructions, and clearly separate them from the rest of the prompt using formatting.
Instructions:
xxx
===
Examples:
Question: xxx
Answer: xxx
Question: xxx
Answer: xxx
Question: xxx
Answer: xxx✨ 4. Retrieval Augmented Generation (or RAG)
One of the worries people have when building GPT-based chatbots is that chatbots might hallucinate. One way to make sure your model doesn't give wrong answers is to inject relevant facts and information about the question asked directly into the prompt.
This technique is called Retrieval Augmented Generation or RAG. Using RAG reduces the chances of the model making mistakes and it also means the model doesn't need to be constantly retrained on new data, which saves you time and money.
Since GPTs have limited context windows, you can't just put all your knowledgebase inside your prompt. A good way is to use search tools to dynamically find facts related to the current question and put them into your prompt.
In an open-domain, consumer setting, when asking questions about any topic, those facts can be found from automatically retrieving relevant information from the internet. In close-domain, enterprise setting, e.g. when asking questions related to a specific area of business, those facts can be taken from your custom domain-specific knowledge base using embeddings based search.
Now let's discuss different variations of RAG.
4.1. Inject data from Google
One way to inject knowledge into your prompt is to input user question into search libraries such as googlesearch-python, get top search results on Google for this user question and inject them into your system prompt, asking the model to use this data to answer user question.
4.2. Use embeddings-based search on raw unstructured data
Another method for implementing RAG is to use embeddings-based search on unstructured raw data. You can create a dataset of relevant documents to your domain, split this data into smaller chunks and assign each chunk an embedding vector which encodes the semantic meaning of the text.
When a user asks a question, their question is also encoded as an embedding. You will then compare the question embedding to the embeddings of each data chunk from your database using a similarity measure, retrieve the most relevant data chunks and paste them into your system prompt. See OpenAI tutorial for more details on how to implement embeddings-based search for question answering. Here are some tips from Peter Isaacs from VoiceFlow on how to prepare your data for RAG.
4.3. Use embeddings-based search on FAQs
Another way to provide even more relevant information to the model is to store your data as a set of FAQs (frequently asked questions). Then, instead of searching through all the raw data, you can try to match the user's question to one of the questions stored in a database. The answers from top most similar matching questions can then be returned and added to the prompt. This approach of storing pre-defined question-answer pairs may be more robust than searching through unstructured raw data. If you want you can read about other advanced RAG techniques here.
✨ 5. Advanced techniques
5.1. Use different prompts for different intents
If you are trying to design for a complex task, instead of writing a long prompt that tries to cover every instruction, try breaking it into smaller parts and using intent classification to determine the best instructions for the current user's query. With intent classification, the system will first detect the intent or type of question being asked. It will then generate the response using the most relevant set of instructions based on the detected intent. This approach helps avoid long, confusing prompts that try to combine every possible type of guidance. It also helps improve accuracy and reduce costs, as longer prompts are more expensive.
For intent detection you can use tools like Rasa or DialogFlow or write a separate GPT prompt, as described in the OpenAI blog.
5.2. Inject a summary of past conversation into the prompt
Because GPTs have a fixed context length, the chatbot can't keep all the conversation with the user in it's memory, which is not ideal. To fix this, you can summarise past conversation history and paste the summary into your system prompt. Read more in this OpenAI blog.
5.3. Inject relevant parts of past conversation into the prompt
Another way to retain information from a long conversation is to dynamically retrieve earlier parts of the conversation that are most relevant to the current question and paste them into the system prompt. Read more in this OpenAI blog.
5.4. Use function calling
Sometimes you want to make your chatbot perform actual actions, e.g. connect to your backend code and do something. You can do that using function calling.
5.5. Other advanced techniques
There are lots of other advanced techniques, here are some you might find useful:
✨ 6. Evaluation
Just as with any other machine learning application, it is very important to have a way to evaluate your models consistently to make sure you are making progress and changes you make in your prompt / chatbot architecture improve the overall performance and don't introduce unexpected bugs.
I will now briefly mention few approaches you can try and share links to other articles where they are described in more detail.
6.1. Manual evaluation
The easiest way to start evaluating your models is by doing in manually. Every time you run a new experiment, compare the responses you get with the gold standard you have in your mind to decide how do you want to change your prompt. To take this a step further, you can have a set list of test questions ready that you will manually evaluate every time you roll out a new version of your prompt to catch any regressions. Do note that this is the slowest and least robust way to evaluate your models. You can start by manually evaluating the outputs of the model and slowly move towards automating your evaluation workflow to make it more repeatable and quantifiable.
6.2. Comparing your model output to ground truth
Another way to evaluate your model is to prepare a data set containing example input questions and the intended correct answers, known as "ground truths." After your ground truth is ready, you will have your model generate responses to the questions from your "ground truth" and calculate the similarity scores between the model outputs and the ground truth answers. The more similar the model responses are to your ground truth data, the better.
To calculate the similarity scores you can use metrics like ROUGE or BLEU, that measure text overlap, or BERTScore, which also computes text similarity but instead of exact word similarity calculates semantic similarity using embeddings. You can read more about those metrics here.
6.3. Evaluating your model output using an evaluation prompt
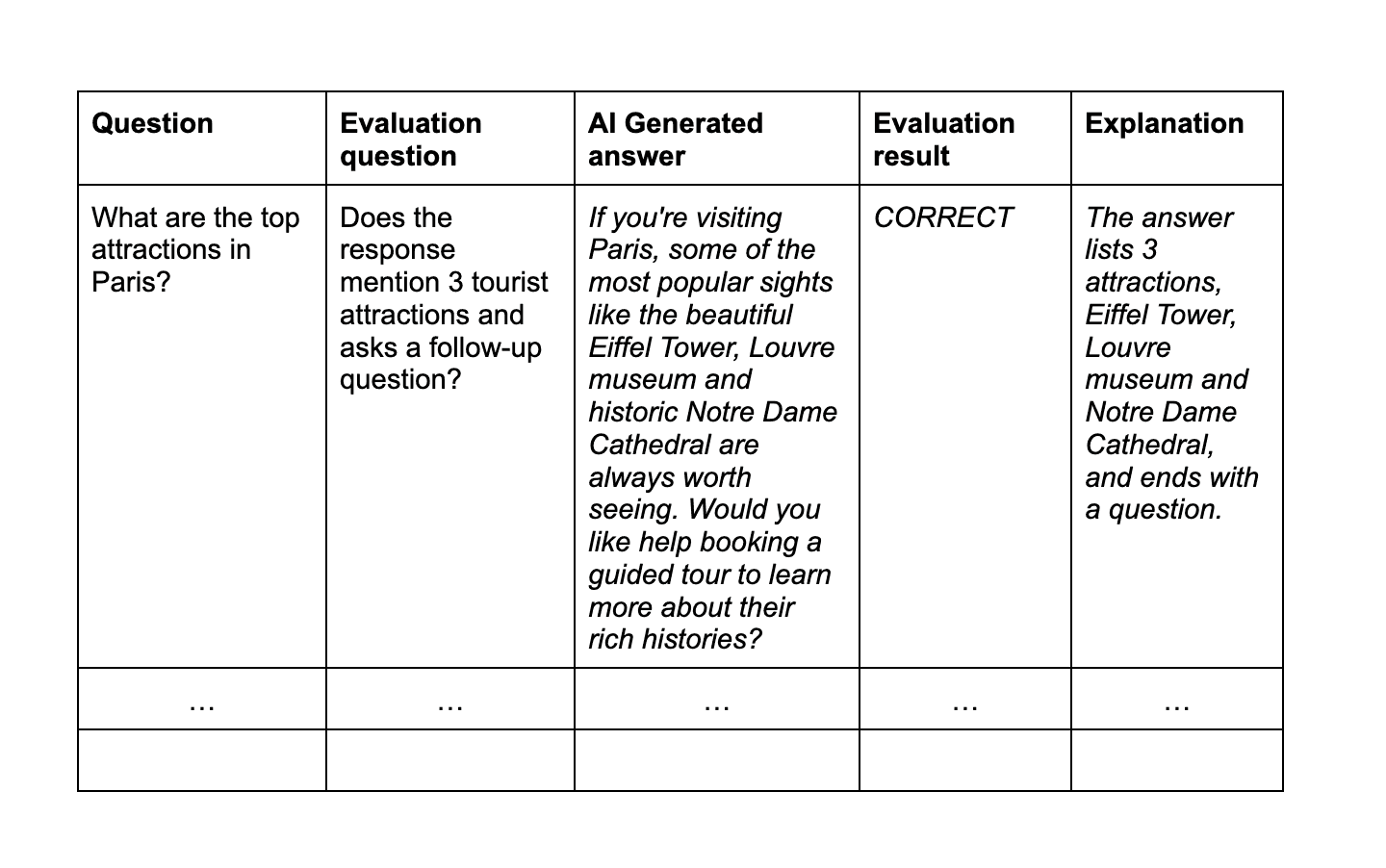
Here is the method I personally like to use for evaluation, which I took from this article. You will again need to create a "gold standard", but in this case it will look different. You will still have a set of test questions, but instead of writing correct answers, you will write an evaluation question, which lists details you expect your AI generated answer to mention.
Here is how your gold standard will look like:
Here is the prompt:
Please answer the question about the text with CORRECT or INCORRECT.
===
Question: {Evaluation Question}
Text: {AI Generated answer}
===
Please make sure the response consists of a single word,
CORRECT or INCORRECT.
Also return an explanation of your response.
Return answer as a dictionary the following format:
{{"Response": , "Explanation": }}A different strategy is described in this article. Here they use a different evaluation prompt to check if the AI generated response answers the original question with relevant information:
You are comparing a reference text to a question and trying
to determine if the reference text contains information
relevant to answering the question.
Here is the data:
[BEGIN DATA]
************
[Question]: {query}
************
[Reference text]: {reference}
[END DATA]
Compare the Question above to the Reference text.
You must determine whether the Reference text contains information
that can answer the Question.
Please focus on whether the very specific question can be
answered by the information in the Reference text.
Your response must be single word, either "relevant" or "irrelevant",
and should not contain any text or characters aside from that word.
"irrelevant" means that the reference text does not contain an answer
to the Question. "relevant" means the reference text contains
an answer to the Question
The last technique I want to mention is described in this Open AI blogpost.
✨ 7. Resources
There is already quite a lot of information on the topic of prompt engineering, LLMs and evaluation. I would like to briefly mention some resources that I found particularly useful in my research.
General prompt engineering tips:
- Curated prompt engineering resources
- Fundamentals of prompt engineering by Human Loop
- Basics of prompt engineering by OpenAI
- More advanced prompt engineering by OpenAI
- Prompt Engineering mini course by deeplearning.ai
- Basics of prompt engineering by Microsoft
- More advanced prompt engineering by Microsoft
- Very expensive article on prompt engineering by Imaginary Cloud
- Advanced RAG strategies by LangChain
Advanced prompt engineering techniques:
- Collection of advanced techniques by Prompting Guide
- Short list of most popular advanced LLM techniques
- Long collection of advanced LLM techniques from research papers
- Classification of advanced prompt engineering techniques
- Blog by Cobus Greyling
Evaluation tools:
Usefull blogposts on the topic of evaluation:
- The Guide To LLM Evals: How To Build and Benchmark Your Evals
- Evaluate model outputs with reference to gold-standard answers
- Testing Language Models (and Prompts) Like We Test Software
- Steady the Course: Navigating the Evaluation of LLM-based Applications
- Semantic Answer Similarity for Evaluating Question Answering Models
- How to Evaluate, Compare and Optimize LLM Systems
✨ 8. Final words
There are lots of articles written on best practices for prompt engineering and it can be easy to get lots in the amount of information available. I hope this blogpost helped you get a nice overview of techniques that are useful for chatbot development specifically and gave you inspiration on how to improve your GPT-based chatbot.
If some of the ideas resonated with you and you want to discuss them further, I'm always happy to connect on LinkedIn. I enjoy talking about this stuff and discovering new ways of building better chatbots together.
Take care!
Lena Shakurova
AI trainer and hands-on engineer with a research degree in Artificial Intelligence and 8 years of building conversational AI. Founder of ParsLabs, helping 110+ organisations design and evaluate AI that works in production.
Send an enquiry →